Basics of Convolutional Neural Networks using Pytorch Lightning
Convolutional Neural Network (CNN) models are a type of neural network models which are designed to process data like images which have spatial information. Convolutional Neural Networks have found success in fields like Computer Vision.
Why CNNs?
Artificial Neural Networks are not designed to process data like images which have spatial information. Hence, to feed images to an artificial neural network, we would have to flatten them which leads to a loss of spatial information.
On the other hand, Convolutional Neural Networks perform Convolution on images using randomly initialized kernels which are later updated during back propagation.
Convolutional Neural Networks are equivariant, this means that the resultant feature map obtained by first augmenting and then performing convolution is the same as the feature map obtained by first performing convolution and then performing augmentation. This property makes convolutional neural networks invariant to spatial transformations.
Working of Convolutional Neural Networks
Convolutional Neural Networks are composed of 3 components:
- Feature extractor — this component is responsible for performing convolution on images and extracting spatial information.
- Flattening — this component is responsible for converting the multi-dimensional feature map to a 1D array which can later be processed by the classification head.
- Classification head — this component is composed of several fully connected layers which perform classification.
Feature Extractor (also known as Convolution block)
This component comprises of various convolution blocks which perform convolution on images to extract spatial information from them.
A Convolution block is composed of the following components:
- Convolution layer
- Activation function
- Pooling layer
Convolution layer
This layer performs the convolution operation on the image to extract spatial information

Terms related to convolution.
- Kernel — this is the filter which is used to perform convolution on images.
- Stride — this is the number of pixels by which the kernel moves while performing convolution.
- Padding — this is the number of pixels by which the image is padded while performing convolution. This is usually done to preserve the image size after performing convolution as the convolution process leads to the reduction in image size.
- Kernel size — this is the size of the kernel which is used to perform convolution on the images. Using a larger kernel size leads to faster training but loss of details in the image
- Number of filters — this is the number of convolution filters which are convoluted on the images. Each filter is stacked along the channels.
Activation function
This is a function which is used to introduce nonlinearity in the feature maps. This is done to enhance the learning process as the result of a series of convolutions without nonlinearity is the same as the result of a single convolution using a different kernel. Hence, by introducing nonlinearity, we enable the convolutional neural network to learn more complex patterns.
Pooling
Since the repeated convolutions on an image leads to an increase in the parameters which lead to increased training time, we use the pooling technique to reduce the number of parameters while preserving the maximum information.
Pooling is achieved by sliding a window (usually 2x2 window) over the resultant feature map and pick up the pooled pixel in each window. Pooling can be of the following types.
Pooling helps to drastically reduce the number of parameters while preserving the information from the image.
- Max Pooling — We pick up the pixel which has the maximum value in each pooling window.
- Min Pooling — We pick up the pixel which has the minimum value in each pooling window.
- Average Pooling — We average all the pixels in the pooling window.
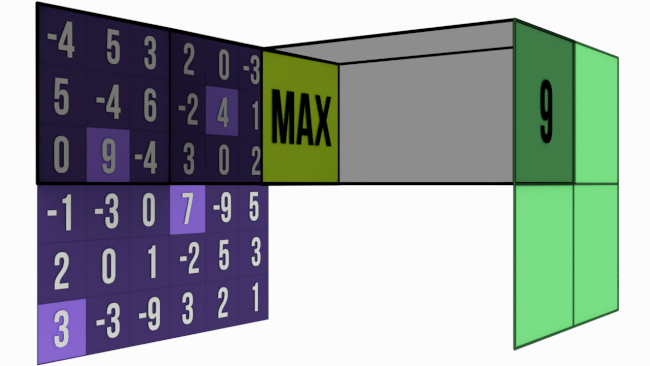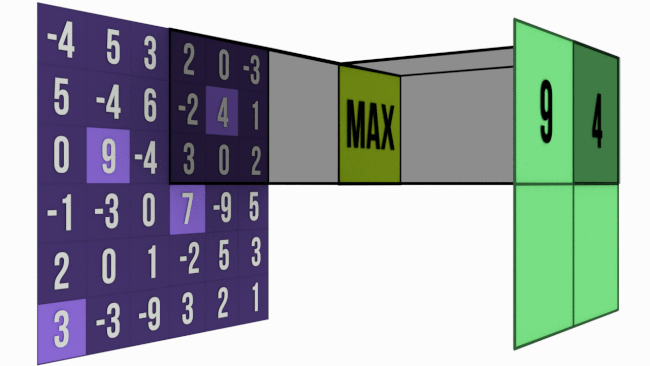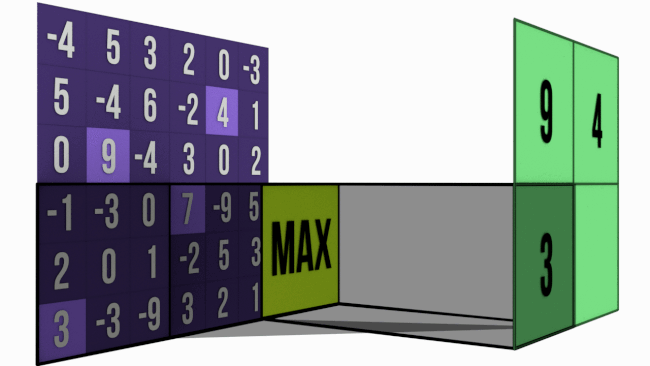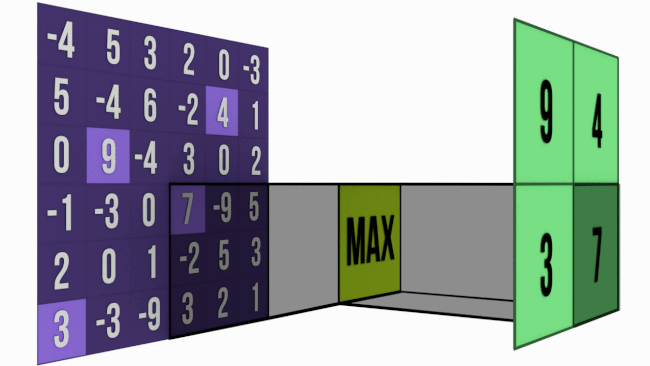
We use the convolution formula to determine the size of the resultant image.

In the convolution formula, we use 2*p because we are adding the padded pixels on both sides of the image.
We subtract the kernel size as the kernel moves across the entire image hence it requires (n-k) steps to cover the entire image.
We divide the strides as the image as the strides is the number of steps the kernel moves after “each” kernel operation.
For calculating the size of the resulting pooled image after the pooling process, we perform floor division of the size of the image by the size of the pooling window.
Loss function in CNN
CNNs are used for a variety of image problems like image classification and image regression.
For image regression, the following loss functions are used:
- MSE
- MAE
- Huber Loss
For image classification, the following loss functions are used:
- Hinge Loss
- Cross Entropy Loss
Tricks to speed up learning
- Use batch normalization — This approach has 3 advantages — speeds up training, allows for a large learning rate and does not depend on weight initialization.
- Use Global Average Pooling instead of Flatten to convert output to 1D array for classification head, this approach captures the information of the feature map in each channel by taking the average and at the same time, it reduces the number of parameters required to train.
How do CNNs learn
CNNs preserve the spatial information of the image by extracting the feature maps. By performing convolution using multiple filters, the CNN learns a variety of spatial information like edges, shapes, objects etc. from the image which are then flattened and passed to the classification head to predict the classes or the regression head to predict the desired quantity.

Check out the Kaggle Notebook for the entire code
Kaggle Notebook:- Basics of CNN with pytorch lightning | Kaggle
